| INTRODUCCION |
En los ºltimos aþos han ido apareciendo nuevas aplicaciones en el mundo de las telecomunicaciones,
que requieren una continua mejora de los equipos terminales y de los canales de comunicaciµn. El
desarrollo y la explotaciµn de nuevos sistemas de comunicaciµn como la videoconferencia o la videotelefonÚa,
deben tratar de compaginarse con la necesidad de aprovechar canales de transmisiµn de baja capacidad,
que en un principio fueron diseþados para transmitir voz o texto [16].
Algunos ejemplos son la red
digital de servicios integrados (ISDN, con tasa de transmisiµn de 64 Kbps), las redes telefµnicas
pºblicas (PSTN's, a 28,8 Kbps) o las redes de telefonÚa mµvil (GSM, a 10 Kbps). La necesidad anterior ha
impulsado el diseþo de tÕcnicas de codificaciµn que permitan trabajar con unas tasas de transmisiµn
restringidas, manteniendo una calidad aceptable.
Una de las caracterÚsticas mÃs importantes de las seþales de vÚdeo es que presentan una gran
redundancia espacial y temporal. El objetivo de las tÕcnicas de compresiµn de vÚdeo es reducir
esa redundancia para disminuir asÚ el ancho de banda necesario para transmitir la seþal.
La redundancia espacial se da dentro de una misma imagen y supone que el valor de cada pÚxel estÃ
muy relacionado con el de sus pÚxeles vecinos. Las imÃgenes naturales estÃn compuestas bÃsicamente
por Ãreas limitadas por contornos. Estas Ãreas suelen ocupar la mayor parte de la imagen, y tienen
la caracterÚstica de que al recorrer sus pÚxeles, el color y la iluminaciµn cambian muy
suavemente. Actualmente se emplea la DCT
[22] (Discrete Cosine Transform) para reducir la
redundancia espacial. La redundancia temporal se refiere a la fuerte correlaciµn que hay entre pÚxeles vecinos a
lo largo del tiempo. En una secuencia se lleva a cabo un muestreo temporal, que debe cumplir el
criterio de Nyquist para que el observador no detecte dicho muestreo. Esto supone que la diferencia
entre dos cuadros consecutivos de una secuencia sea muy baja, existiendo a veces Ãreas que no cambian
en toda la secuencia. AdemÃs, los cambios entre cuadros suelen obedecer mÃs al movimiento de los objetos
de la imagen, que a la apariciµn de nuevos contenidos. Las tÕcnicas de estimaciµn y compensaciµn de
movimiento son las que tratan de reducir la redundancia temporal.
Tratando de combinar las tÕcnicas de estimaciµn y compensaciµn de movimiento con la codificaciµn
mediante DCT, surge el modelo de codificaciµn hÚbrido [4][11], cuyo diagrama de bloques puede
verse en la figura:
|
|
Diagrama de bloques de un codificador hÚbrido.
|
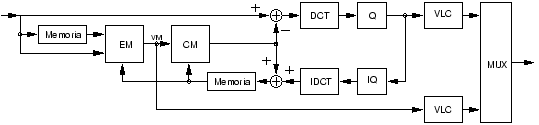
|
EM : Estimaciµn de movimiento
CM : Compensaciµn de movimiento
DCT : Discrete Cosine Transform
IDCT : Inverse Discrete Cosine Transform
Q : Cuantificador
IQ : Cuantificador Inverso
VLC : Variable Length Code
VM : Vectores de movimiento
|
En el modelo anterior, el bloque de estimaciµn del codificador estima el movimiento entre dos cuadros
sucesivos de una secuencia; el bloque de compensaciµn calcula la predicciµn, y entonces se transmite al
decodificador la informaciµn de movimiento junto al error de la predicciµn codificado mediante la DCT.
Dicho error consiste en la diferencia entre el cuadro reconstruido y el cuadro real, y es lo que se llama
diferencia con el cuadro desplazado o DFD (Displaced Frame Difference). La DCT hace un anÃlisis armµnico
de esta imagen, y extrae una serie de coeficientes que representan el peso de sus distintas frecuencias espaciales.
Esos coeficientes se cuantifican, lo que provoca una reducciµn del nivel de detalle respecto a la imagen
original. Sin embargo, el ojo humano pierde su capacidad de detectar el detalle con la frecuencia, por lo que
la cuantificaciµn de los coeficientes de las frecuencias mÃs altas puede ser realizada de forma mÃs grosera
sin afectar en exceso a la calidad. Por tanto la ºnica pÕrdida de informaciµn en este mecanismo se debe a
esta cuantificaciµn de los coeficientes. El rendimiento de la DCT es muy grande gracias a que los valores de los
pÚxeles de la DFD van a ser muy bajos y en muchos casos nulos. En el decodificador se emplea la informaciµn
recibida para construir el cuadro actual, basÃndose en el cuadro anteriormente reconstruido.
El interÕs de este proyecto se centra en los bloques de estimaciµn y compensaciµn de movimiento. El
objetivo es partir de unos modelos de estimaciµn y compensaciµn ya diseþados, y aplicar sobre ellos un
algoritmo iterativo con vistas a mejorar la estimaciµn. De este modo se consigue una reconstrucciµn de
mayor calidad, el error disminuye, y por tanto el rendimiento de la DCT aumenta y se transmite menos
informaciµn al decodificador. Los modelos de estimaciµn y compensaciµn de movimiento de partida estÃn
basados en deformaciµn de mallas, tÕcnica que tambiÕn es conocida como interpolaciµn por control de
malla o CGI [11] (Control Grid Interpolation):
- El primero de ellos emplea una malla regular triangular.
- El segundo usa una malla triangular adaptada al contenido visual de la escena, mediante la adecuada
elecciµn de los nodos de la malla.
- Los esquemas basados en segmentaciµn estÃn recibiendo un creciente interÕs [15], porque
permiten las discontinuidades de movimiento, frente a los dos modelos anteriores que imponen la
conectividad global de la malla. Por ello, este tercer modelo està basado en objetos y trabaja con
imÃgenes segmentadas.
Puede verse que los modelos anteriores constituyen un recorrido desde modelos de primera generaciµn, hacia
otros mÃs cercanos a la segunda generaciµn. Sobre todos ellos se ha aplicado un proceso iterativo llamado
ajuste hexagonal o hexagonal matching [16] (en realidad a los dos ºltimos modelos se ha aplicado
el ajuste poligonal, que es una modificaciµn del ajuste hexagonal para adaptarlo al caso de mallas no regulares),
con el objetivo de refinar los resultados de la estimaciµn de movimiento. Esto permite una mejor reconstrucciµn,
y una reducciµn del error de la imagen predicha respecto a la real.
|
|